Building agents for on-call and incidents?
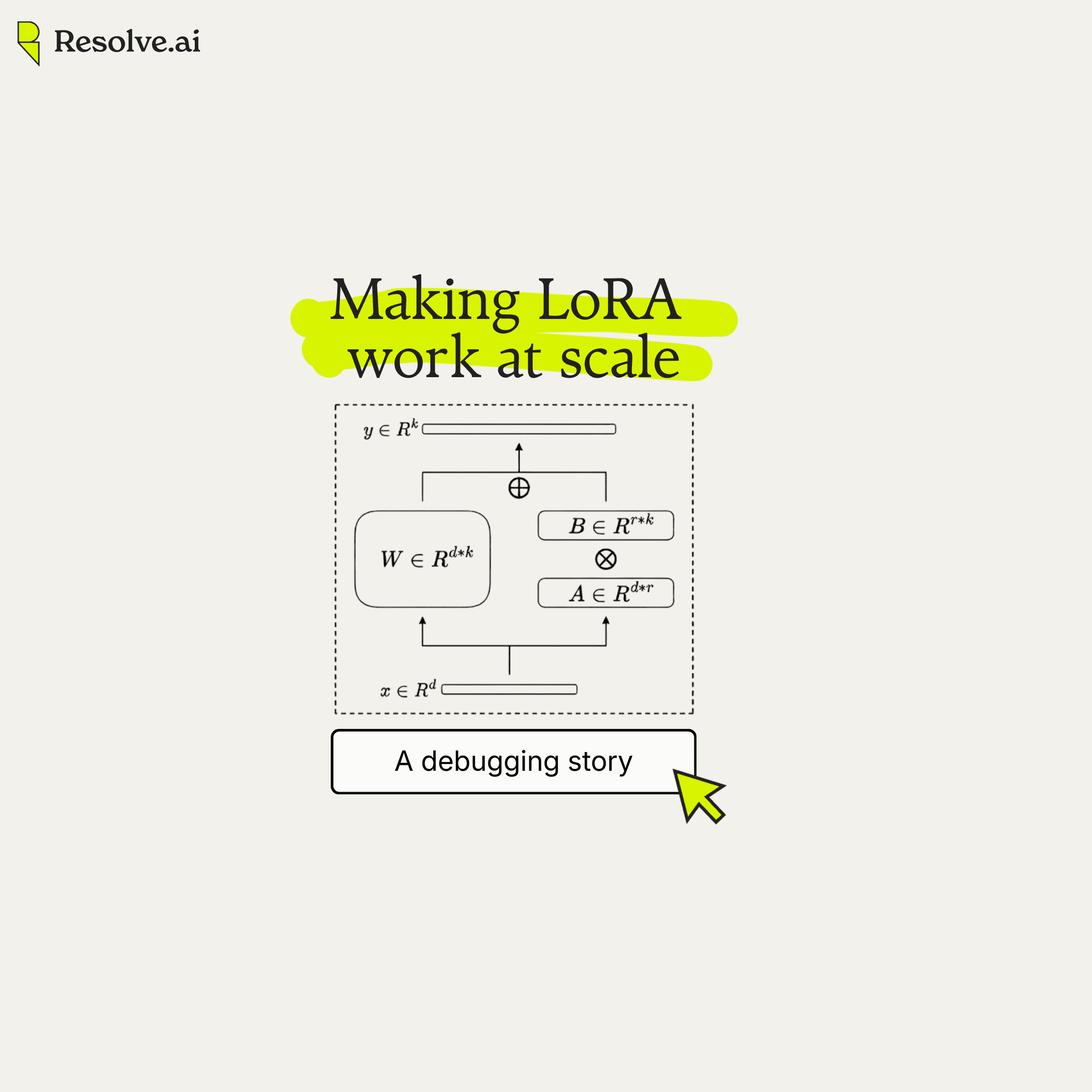
At Resolve AI, we also train and fine-tune models as part of our infrastructure. Recently, we scaled up our LoRA training (Low-Rank Adaptation) to distributed multi-GPU setups.
By every measure we'd normally check, training went well. The model generated correct outputs and the loss curve converged cleanly. Normally, you'd look at this progress and move to evals.
But here's what we found: Our internal evals weren't hitting the scores we expected. The LoRA-trained model generated plausible text but scored worse on evaluation than training loss suggested. The root causes were two silent bugs in the training pipeline, neither of which produced errors or warnings. We caught them through a controlled memorization test and systematic elimination.
I'd encourage you to enjoy the journey before the destination, but if you want to skip ahead, you can jump straight to what we found in “The breakthrough” section.
Our internal evals weren't hitting the scores we expected. Training loss went down, accuracy went up. But not by nearly as much as we'd expect, which smelled like a classic training bug.
We looked at the traces. The model's tool calls were diverging from expected behavior right from the start of each example. Not subtly drifting partway through, but different from the very first call. That shouldn't happen for a model that's supposedly learned.
So we looked at the log probabilities. We have tooling that renders per-token log probs as a heatmap, which makes it easy to spot where a model is confident versus surprised. We compared the base model and our LoRA-trained model side by side on the same data. The trained model was barely distinguishable from the base: which is a slight improvement, but nowhere near what you'd expect from a model whose training loss says it learned the data.
The model still generated reasonable text. If you just read the outputs, you might not notice a problem. But the eval scores, the traces, and the log probs were all telling the same story: the weights weren't quite right. The question was whether this was just noise or a real issue.
To get a definitive signal, we designed a controlled experiment: fine-tune a large MoE model with LoRA and train it to heavily overfit on a small memorization dataset. If the model can perfectly reproduce training data at inference time, the pipeline is working. If it can't, something is broken. No ambiguity.
We trained until it converged. The training loss hit ~1e-4, which meant the model is fitting the training data well. It reproduced every training example word for word.
Then, we loaded the checkpoint into SGLang (inference serving framework) and measured cross-entropy on the same data the model had just memorized.
Training loss: ~1e-4. Inference loss: ~0.03. This was a 300x gap. Same model, same data, same loss metric.
We rendered the per-token log probabilities side by side:
 FIGURE: Per-token log probability heatmap. Green = high confidence, red = low confidence. Tool names and tokens are illustrative.
FIGURE: Per-token log probability heatmap. Green = high confidence, red = low confidence. Tool names and tokens are illustrative.
| Expected output from a correctly checkpointed model with uniform high confidence across all tokens. | Actual output after loading from checkpoint with scattered low-confidence tokens on words the model had perfectly memorized during training |
The model should have been confident on every token. Instead, it was second-guessing words like "from" and "by": words it had reproduced flawlessly during training. The gap wasn't noise. Something between training and inference was silently degrading the weights.
To find the bug, we mapped out every variable in the pipeline that could cause the gap: Fine-tuning method, Model architecture, Inference framework, Precision, LoRA application, Parallelism configuration, and Checkpoint method
The goal was to change one variable at a time until we found the one that mattered. We worked through a series of hypotheses, testing each one against the memorization benchmark.
This was the first thing we checked. Distributed training with Megatron-Core involves a lot of moving parts: MoE routing across expert-parallel ranks, tensor-parallel communication for attention and MLP layers, gradient accumulation across data-parallel groups. A subtle bug in any of these could silently corrupt what the model learns.
To test this, we ran the same experiment with full fine-tuning instead of LoRA. Same model, same parallelism config, same memorization dataset. If full SFT also showed a gap, the problem would be in the training infrastructure itself.
It didn't. Full SFT on a dense model gave us a training loss of 9.59e-6 and an inference loss of ~9e-6. Essentially identical. We repeated this on MoE architectures with multiple parallelism configurations (different TP, PP, EP combinations). Every single one matched.
| Method | Training Loss | Inference Loss | Gap |
|---|---|---|---|
| Full SFT (Dense) | 9.59e-6 | ~9e-6 | 1x |
| Full SFT (MoE, TP=4, EP=2) | ~0 | 7e-6 | ~1x |
| Full SFT (MoE, TP=1, EP=8) | ~0 | ~0 | 1x |
| LoRA (MoE) | ~1e-4 | ~0.03 | ~300x |
We also tested across different model sizes and architectures (both dense and MoE) to rule out model-specific issues. Full SFT matched in every case. Megatron's training infrastructure was sound. The issue was LoRA-specific.
LoRA adds a low-rank adapter to the base model's weights. At inference time, you have a choice: apply the adapter on the fly ("online LoRA") or merge it into the base weights permanently. Different frameworks implement this differently, and any of them could introduce errors. Maybe SGLang's FP8 KV cache was quantizing something it shouldn't. Maybe the PEFT merge operation was losing precision.
We tested seven different inference configurations on the same checkpoint. Every method landed in the same range:
| Inference Method | Precision | Loss |
|---|---|---|
| SGLang (production, FP8 KV cache) | BF16 + FP8 | ~0.058 |
| SGLang (all optimizations disabled) | BF16 | ~0.025 |
| HuggingFace online LoRA | FP16 | 0.030 |
| HuggingFace online LoRA | BF16 | 0.030 |
| HuggingFace online LoRA | FP32 | 0.030 |
| PEFT merge_and_unload | FP16 | 0.030 |
| Native FP32 merge (bypass PEFT) | FP32 | 0.028 |
Online LoRA (no merge) gave the same result as merged weights. FP16, BF16, and FP32 all agreed. When that many independent implementations produce consistent results, the bug is upstream. Something was wrong with what gets saved, not how it gets loaded.
This one looked promising. Almost too promising. BF16 has only 8 bits of mantissa compared to FP16's 11 bits. When merging LoRA weights (W' = W + α·B·A), the low-order bits of the LoRA delta get rounded away because they fall below W's representable precision. This order of operations matters because floating-point arithmetic isn't associative: (W + α·B·A)·x ≠ W·x + α·B·A·x. Computing them separately preserves more of the correction. These errors compound across transformer layers.
We measured the per-layer difference between applying LoRA online versus merging it into the base weights:
| Precision | Max Per-Layer Diff | Relative Error |
|---|---|---|
| FP32 | 0.000001 | 0.001% |
| FP16 | 0.003906 | 2.5% |
| BF16 | 0.031250 | 19.75% |
BF16 had 8x worse associativity error than FP16, and this compounds across multiple transformer layers. For a moment, it felt like we'd found the answer.
But switching to FP16 or FP32 for inference didn't meaningfully reduce the overall loss gap. The end-to-end gap remained in the same range of ~0.028–0.030, regardless of precision. The precision error was real and measurable, but something much larger was drowning out the signal. We set it aside and kept looking.
Converting a checkpoint from Megatron's internal format to HuggingFace PEFT format involves reshaping tensors, renaming parameters, and applying the LoRA merge formula. Any of these steps could introduce errors.
We checked every step of the conversion pipeline: weight tensors compared element by element (max difference: 2.98e-8, noise floor), LoRA merge formula verified layer-by-layer at 1e-6 tolerance, scaling confirmed identical at alpha/rank = 32/128 = 0.25, LayerNorm fusion, RoPE positional encoding, softmax precision, and loss computation all matched.
Everything checked out. The math was right. The weights we had were being applied correctly. The problem was that we didn't have the right weights.
We had eliminated precision, merge math, and weight conversion. Every inference method agreed on the same wrong answer. That consistency pointed upstream, but we needed to pinpoint exactly where.
So we cut inference out of the equation entirely. Instead of converting checkpoints and loading them into SGLang or HuggingFace, we ran evaluation directly inside Megatron using its native eval path. Same training code, same model and configs in memory, no conversion, no external inference framework.
We also added an in-training validation step that evaluates the model before saving. If the model is correct in memory but broken after save/load, the checkpoint is the problem.
| Test | Training Loss | Eval Loss | Gap |
|---|---|---|---|
| In-training validation (before save) | 1.26e-5 | 1.34e-5 | 1.07x |
| After checkpoint save/load | 1.35e-4 | 0.00658 | 50x |
The model was correct in memory. The checkpoint was corrupting it.
To confirm, we wrote a custom export that bypassed Megatron's distributed checkpointing entirely. Instead of going through dist_checkpointing.save(), we gathered the adapter state dicts from all ranks and wrote them with raw torch.save(). Loaded them back. Ran evaluation.
| Checkpoint Method | Training Loss | Eval Loss | Gap |
|---|---|---|---|
| Standard Megatron checkpoint | 1.35e-4 | 0.00658 | 50x |
| Custom .pt export | 2.47e-5 | 2.54e-5 | 1.03x |
Same model. Different checkpoint method. The training code was correct. The inference code was correct. The checkpoint save was dropping adapter weights.
With tensor parallelism, a model's weight matrices are split across multiple GPU ranks. Rank 0 holds one slice, rank 1 holds another. When you add LoRA adapters to these layers, the adapters get sharded the same way. Each rank has its own slice of each adapter.
The problem: these shards have identical parameter names but different tensor data. Rank 0's layer.0.lora_A.weight contains different values than rank 1's layer.0.lora_A.weight. Both are needed to reconstruct the full adapter.
During PEFT-filtered checkpoint save (which saves only adapter weights, not the full model), each TP rank creates a ShardedTensor for its adapter shard with the same logical key. These shards should be distinguished by their tensor offsets, but during the distributed save coordination, they end up being treated as duplicates. The result is that only one TP rank's shard gets persisted:
# What should happen:
# Rank 0: "layer.0.lora_A.weight" → shard [0:rank/2, :] → saved
# Rank 1: "layer.0.lora_A.weight" → shard [rank/2:rank, :] → saved
# What actually happens with PEFT-filtered save:
# Rank 0: "layer.0.lora_A.weight" → shard [0:rank/2, :] → saved
# Rank 1: "layer.0.lora_A.weight" → shard [rank/2:rank, :] → silently dropped
No errors, no warnings. Just missing data.
The model still worked because partial weights were preserved. Enough to produce plausible text, but not enough to match the model that was actually trained.
We've narrowed the root cause to the PEFT-filtered distributed checkpoint save path. We filed a bug and NVIDIA’s Megatron-Bridge team is helping us investigate the exact codepath responsible. Previously, NVIDIA's Megatron-Bridge team had already identified and fixed a related issue for expert-parallel adapters in MoE layers (PR #1564, related to volcengine/verl#4303), where TP shards weren't being properly distinguished. We believe the same mechanism applies to dense LoRA adapters and we're working together with their team to investigate the issue.
We implemented a workaround: temporarily disable the PEFT filter during checkpoint save, forcing the full model state dict to be saved. The full model save path already handles TP sharding correctly, so all adapter shards are preserved. The trade-off is larger checkpoint files, but the weights are correct.
# Workaround: disable PEFT filter to preserve TP shards
peft_backup = state.cfg.peft
state.cfg.peft = None # Save full model (preserves TP sharding)
try:
save_checkpoint(state, model, ...)
finally:
state.cfg.peft = peft_backup # Restore config
We've shared a reproduction case and our analysis with NVIDIA's Megatron-Bridge team, and we're actively working with their engineers on test coverage and a robust upstream fix. The proper solution would ensure that TP shards of dense adapters are correctly distinguished during PEFT-filtered save, likely mirroring the handling that already exists for expert adapters.
With the checkpoint bug fixed, we circled back to the precision finding we'd set aside earlier. The per-layer BF16 associativity errors were real. The checkpoint corruption had been drowning out the signal: like trying to hear a conversation next to a fire alarm. Once the alarm was silenced, the conversation became audible.
In some ways, this is the more interesting finding. Checkpoint corruption is a software bug: someone missed an edge case, you work together on a fix, it gets resolved. BF16 precision loss is structural. It's a property of the arithmetic format that most large-scale training relies on. BF16 offers good dynamic range with lower memory and compute cost, but the trade-off is reduced mantissa precision, and that has real consequences when LoRA adapters need to be applied with exact fidelity across dozens of transformer layers.
The mitigation is straightforward: use FP16 or higher precision when applying LoRA weights at inference time, regardless of the precision used during training.
We found two bugs in the same pipeline. One was a software bug: checkpoint serialization silently dropping adapter weights. The other was a numerical property of BF16 arithmetic compounding errors across transformer layers. Different in kind, both real, both capable of silently degrading the quality you paid for with training compute.
The checkpoint bug ended up in the most mundane part of the pipeline: serialization. Not the model. Not the math. Not inference. Just how a checkpoint gets written to disk. It affects anyone using LoRA with tensor parallelism in Megatron-based training. The precision bug affects anyone using BF16 for LoRA weight application, regardless of framework.
What got us there was process. The memorization test gave us a controlled, reproducible signal. Changing one variable at a time let us isolate the layer of abstraction that was broken. When configuration changes couldn't explain the problem, we bypassed entire subsystems until we found the one that mattered. And when the big bug was fixed, the smaller one became visible.
Distributed training has sharp edges where parallelism strategies meet adapter methods. As LoRA adoption grows, we expect more issues like this. We're investing in validation tooling that catches these discrepancies before deployment, and contributing fixes upstream when we find them. These frameworks are shared infrastructure. Bugs affect everyone, and so do fixes.
At Resolve AI, we're building AI for prod: agents that help engineers operate production systems across code, infrastructure, telemetry, and knowledge. Building these agents means training our own models and solving hard problems across ML infrastructure, distributed training, model evaluations, and more. If that's the kind of work that excites you, we'd love to talk.

Join our engineering leads for "Behind the Build", a webinar series deep-dive into how we built agents that run software.

The question isn't whether AI belongs in production anymore. Here's what engineers at AWS Summit NYC 2026 told us about how agents run your software, what guardrails they want, and how the pricing should work.

A frontier model can produce a thousand coherent answers. Most enterprise work needs exactly one correct one, and closing that gap is not a bigger model. It is the agent architecture around it. Here are the six layers that turn open-ended capability into a defined outcome, and why production incidents are the hardest test of whether they work.

Watch how Resolve AI investigates a service timeout from application logs through Kubernetes pods down to failing memory modules in a UCS blade - building a complete causation chain in 3 minutes. See the stark contrast between traditional multi-team incident response (4 teams, multiple tools, hours of coordination) and AI-native investigation that maps dependencies from app code to storage infrastructure without organizational handoffs. Learn why engineering silos slow incident response and how AI agents can reason across the entire production stack as one connected system.
