Building agents for on-call and incidents?

I've been debugging production systems for over seven years and appreciate the real-world complexity that on-call responders deal with. Last week, while helping a customer onboard, I was pleasantly surprised when Resolve AI investigated a service timeout issue to a hardware problem within minutes. Previously that would have involved four teams, multiple tools, multiple tickets, and hours of engineering time lost in finding out the root cause.
Here is a typical timeline of investigating a similar service timeout issue:
Instead, I watched Resolve AI trace the issue from the application through Kubernetes pods, past Linux server nodes, down to the failing memory modules in UCS Chassis 7, Blade 7 – building a complete causation chain in just three minutes!
What happened here? Resolve AI connected the dots across both software and hardware worlds, navigating through what would normally require multiple team handoffs and tool switches. It connected applications to services to pods to nodes to hardware, then reasoned through that entire dependency chain to find the root cause.
Here is a typical investigation we've recreated based on what we have seen repeatedly across several customers: where hardware issues manifest as application problems, but the connection between them requires expertise across multiple teams.
Here is a contrast of how the investigation went with Resolve AI, compared against what usually happens in such cases:
| Manual investigation path | Investigating with Resolve AI |
|---|---|
| Step 1: Service team investigation Alert fires on frontend latency → Check application logs and metrics in Datadog → Contact Frontend team: "Did something change? I’m seeing an increase in retries" → Wait for confirmation | Complete analysis Ask a question to Resolve AI “I am seeing a latency on the frontend. What is the issue?” |
| Step 2: Escalate to platform team Create incident ticket in ServiceNow → Platform teams checks k8s dashboard in tools like Rancher → "Pods are healthy after restart, maybe it's application load" | Resolve AI maps: App → service → pods → UCS blade → Storage cluster Provides complete list of dependencies |
| Step 3: Infrastructure team is looped in “This keeps happening. Can we get the infra team involved?" → Escalate to Infra team → SRE checks the node health in Prometheus → "Nodes look fine, but let's check hardware" → contacts infrastructure team | Provides complete list of dependencies Service degradation due to storage latency: - 12 pods across 6 namespaces - UCS racks: XXX-XX-XXXXXX (18 chassis, 22 blades) - Specific blade: chassis-7/blade-7 - Storage: NetApp clusters XXX-XX-XX-XXXX - Infrastructure: NetApp cluster correlation identified - Recent correlation: Storage array running outdated firmware version, missing critical I/O performance patch available |
| Step 3: Hardware investigation Infra team SSH to nodes → Check UCS Manager → Contact Hardware team → "Chassis looks healthy" → Escalate to storage team | |
| Step 4: Root cause The storage team logs into NetApp System Manager → "Wait, this array hasn't been patched to the latest firmware. There's a known issue with I/O latency under load" → Apply patch | Root cause: NetApp storage array requires firmware patch to resolve known latency issue under load |
| Total time: Hours Teams involved: 4 different teams Context handoffs: 5-7 ticket updates, potential war rooms | Total time: 3 minutes Teams involved: 1 engineer and an expert for approval Next action: Clear ownership and actionable next steps |
Here is an image of how Resolve AI mapped k8s pods to infrastructure and its dependencies.
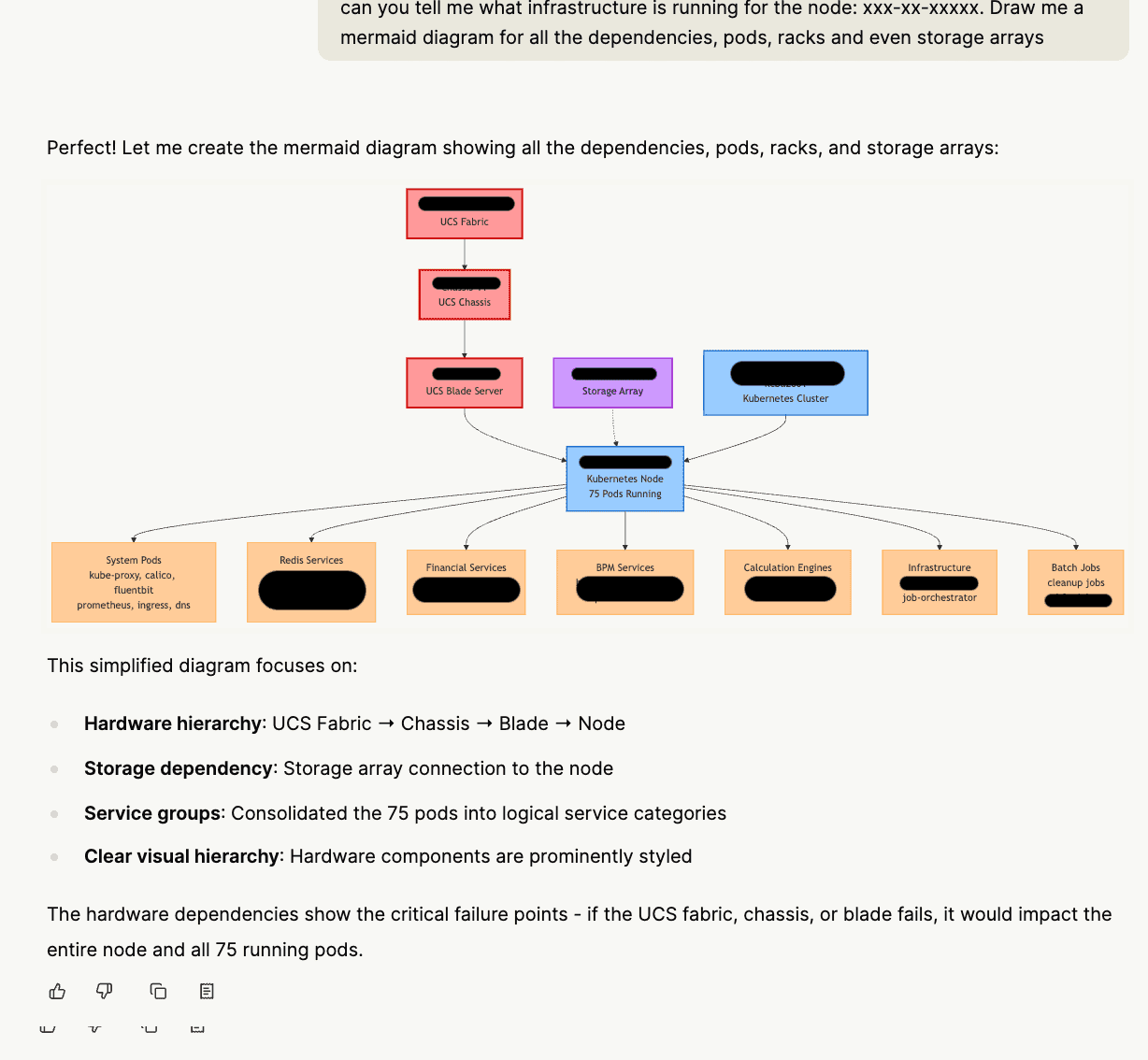
Resolve AI reasoned through the complete infrastructure topology from application code down to specific hardware components and explained why a memory error in a server blade was causing application timeouts.
Engineering expertise lives in silos, and each team specialize in different parts of the stack:
Connecting expertise across these teams, especially during incidents, takes time. This is why war rooms are essential during critical incidents.
Tools are fragmented: Each team has specialized tools they're experts in: DataDog for logs or dashboards, Rancher for Kubernetes, UCS Manager for hardware, NetApp System Manager for storage. No single person can be expert in all these systems, and context gets lost jumping between them.
Changes are too tough to keep up: Our system complexity evolves faster than our process. Continuous PRs, new storage arrays, updated k8s versions, modified network topology, and many more. By the time someone learns the current setup, it's already changed.
Every handoff means tickets, Slack threads, context explanations, and 15-30 minutes of "can you check on your end?" Our incident response wasn't slow because of technical complexity. It was slow because of organizational friction.
AI agents don’t have our limitations or boundaries: Resolve AI treats the entire stack – from application code to storage infrastructure – as one connected system. It builds a comprehensive knowledge graph that connects applications to services, services to pods, pods to nodes, nodes to hardware, and hardware to storage arrays. Instead of fragmented tool views, it maintains a living map of your entire production.
It doesn't need to create tickets, explain context, or wait for responses. It reasons across layers we artificially separated.
Incident investigations: When services start failing, Resolve AI automatically begins investigating before your on-call engineer gets paged. Within minutes, you get the root cause with fix recommendations: "Hardware memory errors in UCS Chassis 7, Blade 7 causing NetApp storage I/O delays. Fix: Migrate workloads, replace memory modules." Your engineer wakes up to solutions, not just problems.
Debugging production: Say you are planning a storage maintenance. You can ask Resolve AI "What will be affected by upgrading the storage cluster xxxx?" You get a complete blast radius: "30+ server nodes, services (100+ instances), Bridge applications (90+ instances) affected. Development/QA environments impacted, production isolated. You can execute changes (even in infrastructure) with complete application impact visibility. No surprise outages, no angry service teams discovering problems after maintenance starts.
Beyond these core scenarios, Resolve AI excels at other use cases like production debugging for any team member (getting precise answers about system behavior) and fast team onboarding (instant answers about infrastructure instead of hunting through documentation). It can also execute actions on your tools like generating kubectl commands or procedures that work with your specific setup.
Resolve AI doesn’t just help you resolve incidents quicker. It is about understanding your production system as an integrated whole rather than isolated layers.
Over decades, we built technical abstractions to manage complexity. Kubernetes hides hardware complexity. Applications hide Kubernetes complexity. Then we also organized teams around those abstractions, creating specializations and expertise silos at each layer.
Systems like Resolve AI can help us see through both technical AND organizational boundaries to understand how our systems actually work. Your next incident doesn't have to be a 2-hour cross-team coordination exercise. It can be a 3-minute investigation with a clear resolution path.
Resolve AI is your always-on AI SRE that helps you resolve incidents and run production.
Founded by the co-creators of OpenTelemetry, Resolve AI understands your production environments, reasons like your seasoned engineers, and learns from every interaction to give your teams decisive control over on-call incidents with autonomous investigations and clear resolution guidance. Resolve AI also helps you ship quality code faster and improve reliability by revealing hidden system context and operational behaviors.
With Resolve AI, customers like DoorDash, Coinbase, Zscaler, and Salesforce have increased engineering velocity and systems reliability by putting machines on-call for humans and letting engineers just code.

Join our engineering leads for "Behind the Build", a webinar series deep-dive into how we built agents that run software.

Iain Methe
Member of Technical Staff
Iain is a member of technical staff at Resolve AI building out its knowledge graph and creating integrations with the tools that SREs use daily. Before joining Resolve AI, he worked at Datadog on incident response tools and event storage systems.

Varun Krovvidi
Product Marketing Manager
Varun is a product marketer at Resolve AI. As an engineer turned marketer, he is passionate about making complex technology accessible by blending his technical fluency and storytelling. Most recently, he was at Google, bringing the story of multi-agent systems and products like Agent2Agent protocol to market

The question isn't whether AI belongs in production anymore. Here's what engineers at AWS Summit NYC 2026 told us about how agents run your software, what guardrails they want, and how the pricing should work.

A frontier model can produce a thousand coherent answers. Most enterprise work needs exactly one correct one, and closing that gap is not a bigger model. It is the agent architecture around it. Here are the six layers that turn open-ended capability into a defined outcome, and why production incidents are the hardest test of whether they work.

Announcing my new role at Resolve AI to lead marketing - joining a mission-driven team reimagining software operations with Agentic AI and building a category-defining company.